Bonjour,
This is the software architecture that will be the first implementation of fedeproxy. It will be presented to @arthurlogilab June 16th, 2021.
It focuses on allowing individual issues to be federated. There is evidence (see the User Research report)
Cheers
Use case
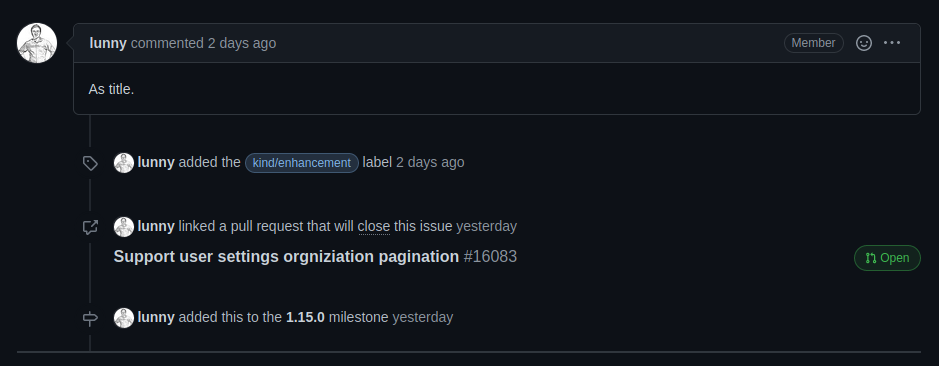
Federating issues
- Issue A is created on Forge A by user A
- Issue B is created on Forge B by user B
- User B adds a link to issue A in issue B
- All comments / edits on Issue A made by user A are copied over to issue B
- All comments / edits on issue B made by user B are copied over to issue A
Adding a comment to an existing issue
- An ActivityPub message of type forgefed comment is received
- The comment is added to the corresponding issue
Notifications:
- All comments / edits are published via ActivityPub as forgefed commits
Constraints:
- User B never comments / edits on Issue A
- User A never comments / edits on Issue B
Users
Users on a given forge are uniquely identified by their public URL (e.g. https://lab.fedeproxy.eu/dachary).
All actions carried out by the proxy on behalf of a given user are attributed to the user from which the action originates. If the user does not exist on a given forge, it is created by the proxy.
- User A exists on forge A
- User A/B is created on forge B to act on behalf of user A
- Credentials for User A/B on forge B are stored in a private repository of the User A on forge A
A user is created by the proxy (i) with administrative privilege on the forge, (ii) by drawing in a pool of unused existing users created manually.
State
The fedeproxy service is stateless.
- Issue data is stored in the software project DVCS (e.g. in an orphan git branch)
- User private information (e.g. users created by fedeproxy on other forges on behalf of the user) is stored in a private project
Issue data format
A JSON based format is created to be used as a pivot format internally.
The forgefed commit is used to represent the issue activity. It is not human readable and is used in server to server communications:
- The commit activity is received
- The forge and project URL of the DVCS are deduced from the context
- The commit hash is checked out
- The issue associated with the commit is deduced from the content of the commit
Software stack
The fedeproxy web service is based on:
- Django for the administrative REST API
- Allauth for authenticating with forges
- Copy/pasting from BookWyrm for ActivityPub
Supported forges
- GitLab (GitLab CE to GitLab CE as the first step)
- GitHub (when GitLab CE support works) with Gitea for CI
Workflow
A fedeproxy instance is responsible for a single forge. For instance if there are two GitLab CE instances, there are two fedeproxy instances.
- When fedeproxy receives a notification via ActivityPub about a new commit hash it:
- Gets the issue state from the originating DVCS using the commit hash
- Converts the pivot format to update the forge via the REST API
User eXperience
- fedeproxy will federate Issue B with Issue A if
- a comment contains @fedeproxy follow URL (for an existing issue or a new one)
- it receives a follows from ActivityPub
- fedeproxy will stop federating Issue B with Issue A if
- a comment contains @fedeproxy unfollow URL
- it receives a[“unfollow” from ActivityPub